October 2017 Update
In October 2017, we introduce a whole new concept: Interface Classification, as well as a ton of additions to the product, read on!
V3 UI with Dark Theme

To any regular user of Kentik Detect the most obvious update is probably our new User Interface (UI), which has a cleaner, more modern layout. Users can now choose between our standard white-background theme or a new dark theme with a darker background. The dark theme is designed to minimize eye fatigue for customers who spend many hours a day looking at large screens. To use the dark theme, hover over your username at the right of the portal navbar, then choose Use Dark Theme from the drop-down menu.

BiDirectional Charting

Have you ever wanted to plot two data series on the same graph? Our new Bi-Directional Charting feature (which replaces V2’s Multi-Data-Series functionality) allows the display of two graphs in one, with the second graph plotted against the negative Y axis. To use this feature, enable it under Advanced Options in the Query pane of the Data Explorer sidebar. You can use this feature either for inversion or for a secondary metric.
By default, turning on Bi-Directional Charting results in inversion, in which the original query (the dimensions and filters you specify) is plotted on the positive Y axis above and the inverse of that query is plotted on the negative Y axis below. The tables corresponding to each graph appear in the Original Query and Opposite Query tabs below the graph.


To plot a secondary metric instead of an inverse query, choose a metric from the drop-down Secondary Metric selector, which is also in the Advanced Options section. After clicking the Run Query button to update the display, both graphs will use your original dimensions and filters, but the positive axis will display results measured in the primary metric while the negative axis will show results in the secondary metric. A simple use case would be to simultaneously see bits/second and packets/second.

Interface Management
In the Admin section of the V3 portal we’ve created a dedicated screen for Interface Management (Admin » Interfaces) which used to be part of Device Management. At top left you choose the device whose interfaces you want to see in the Interface List below, where you’ll find information about each of the device’s interfaces, including description, boundary ASNs, capacity, interface classification, and more.

Among the data points you’ll find on the new Interface Management page is our new Boundary ASNs indicator. This cool new feature uses the flow data collected by Kentik Detect to determine the ASNs your infrastructure connects to directly via your edge interfaces (Network Boundary = External). In the example above you’ll see a “View 2 ASNs” button in the Boundary ASNs column; if you were to click on that button in the example shown, a list would pop up showing the ASNs detected on the interface as well the interface’s traffic to each listed ASN as a percent of the total traffic to that ASN from the entire device.
Interface Classification

Also new to the V3 portal are a number of improvements to the Interface Classification Rules Editor (Admin » Interface Classification; see Interface Classification in the Kentik Knowledge Base). On the Interface Classification page, the Classified Devices Pane at right displays all of the devices your organization has registered in the portal and tells you how many interfaces on each device are classified. If your percent of classified interfaces is anything less than 100, you’ll see an Unclassified Interfaces button that opens the Unclassified Interfaces dialog, where you’ll find information about the interfaces that aren’t being classified by your classification rules.
Speaking of rules, the UI for the Add Rule and Edit Rule dialogs has been improved as well. After creating a rule, you can click the Test Rule button to apply the rule on a test basis and see a list showing how many of interfaces remain unclassified.
For a fuller explanation on using Interface Classification, check out our Interface Classification blog post.
New Version Notification
Our development teams here at Kentik are continually improving Kentik Detect by pushing out new features and bug fixes. We now include a popup notification to users whenever an update is available since the browser was refreshed.

















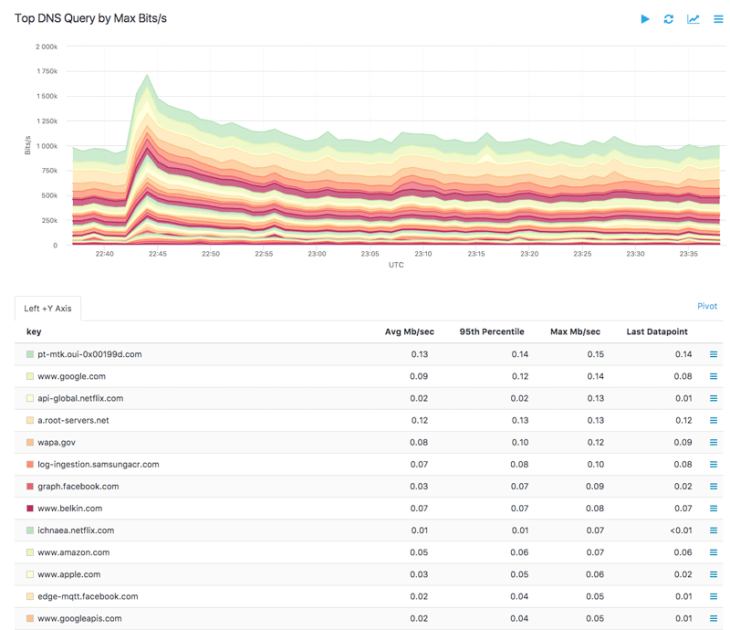
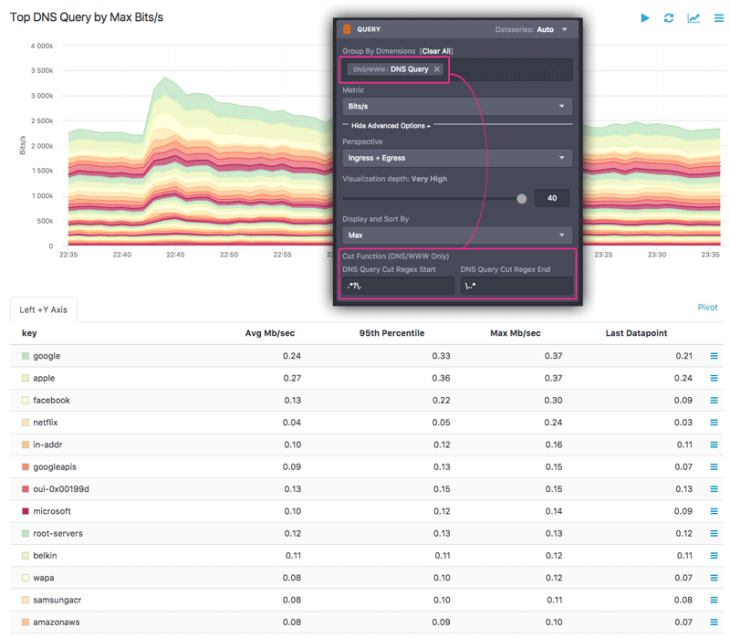




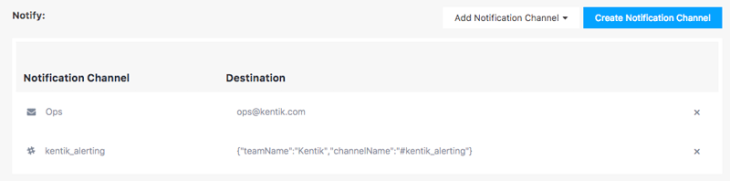
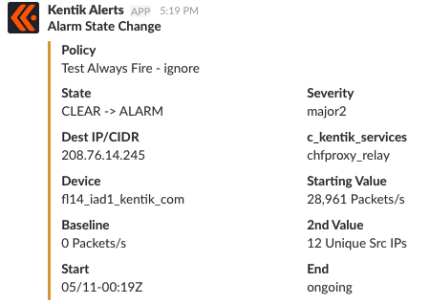
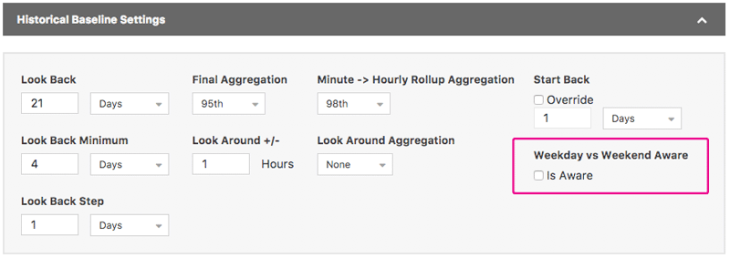
 a button on Alert Policy page that allows you to look at the existing, current flow data against which you are trying to build a policy.
a button on Alert Policy page that allows you to look at the existing, current flow data against which you are trying to build a policy.